The kickoff call goes well. Then the client's payroll data arrives, and not one column matches the format your system needs.
Every implementation leader knows this moment, because it comes around with every new client. They just hand the work to someone else: your implementation managers, or a client who outsourced payroll so long ago they barely recognize their own data.
Either way, the same manual conversion happens over and over, client after client. Your capacity grows only as fast as you can hire, and time-to-first-payroll keeps slipping.
It doesn't have to stay this way. This guide breaks down what the payroll format gap is, what it's costing your organization, and how AI data mapping can close it at the file level.
What is the payroll format gap?
The payroll format gap is the distance between the data a new client can export from their previous payroll provider and the format your payroll system requires before the first run. Your target structure is fixed. The files coming in rarely are.
We hear the same frustrations from implementation teams across payroll, often in nearly identical words:
- Provider-dependent structures. What a client can send depends entirely on which legacy system they’re leaving. Each provider exports differently, and new providers keep appearing that your team sees for the first time mid-project.
- Inconsistent field names. The same data point may arrive as employee number, payroll ID, or works number, depending on the source system. Your consultants only learn the variations through repeated exposure.
- Unstable layouts. Header rows wander between line five and line ten from one delivery to the next. Even standardized outputs, such as UK FPS files, can be interpreted differently by different payroll systems.
- Fragmented deliveries. Employee data often arrives spread across three to six separate reports, with duplicated records that need to be merged on an identifier that’s named differently in every file.
- Hostile formats. Some legacy providers export PDFs instead of structured data as Excel or CSV files. Implementation teams have described these handovers as the most painful part of the entire onboarding.
One implementation leader at a global payroll provider summed up the asymmetry well: clients who’ve outsourced payroll for years often don’t know their own data anymore, yet they’re the ones asked to deliver it in a precise format.
Why templates seemed like the answer, and why they fall short
When every client file looks different, building a template for customer data onboarding feels like the obvious fix. You define the exact columns your system shouldaccepts, hand the spreadsheet to the client or your implementation manager, and ask them to fill it in. The destination is now standardized.
The source, however, isn’t. That’s the structural flaw: a template defines what you need, not how to get there from whatever the client exported. The transformation work between the two formats stays fully manual, and it lands on one of two desks:
- Your implementation managers, who convert legacy exports into the template through copy-paste work and VLOOKUPs, file by file, client by client.
- Your clients, who receive a multi-tab workbook with dozens of mandatory columns and are expected to populate it from systems they may not even have reporting access to.
Either way, the work gets done by hand. As volume grows, the coping mechanism becomes a liability:
- Template libraries sprawl. One payroll software provider’s team maintained around 30 template variations for different source systems. An HR and payroll vendor counted roughly 100 import templates, with 10 to 15 separate imports needed per implementation.
- Validation arrives too late. Format rules often live in hover comments or in nobody’s documentation at all, so CSV import errors typically surface only at the moment of import. Each failed import triggers another email loop with the client – queries sent, files annotated, gaps returned for completion.
- Knowledge stays in heads. Which provider exports what, and how to wrestle it into the template, becomes senior-consultant tribal knowledge. New hires take months to ramp, and a single absence can stall an onboarding.
- Clients push back. Implementation leaders report clients asking why they must retype data their HCM system already holds, and complaining about providing the same information twice across overlapping templates.
A template, in other words, doesn’t close the format gap. It formalizes it.
What the format gap costs your organization
For a VP of Implementation or Director of Service Delivery, the operational pains translate directly into business costs:
| Operational pain |
Business impact |
| Consultants spend hours per client on copy-paste and VLOOKUP work |
Implementation cost per client rises; skilled consultants do spreadsheet work instead of client-facing consulting |
| Error loops run through email, with files bouncing between team and client |
Time-to-first-payroll stretches from days into weeks, delaying revenue recognition |
| Format knowledge lives in senior consultants’ heads |
Ramp time for new hires grows; key-person risk on every project |
| Every new client requires the same manual conversion, even from a known source system |
Onboarding capacity scales only with headcount, hiring becomes the growth ceiling |
| Clients struggle with template workbooks |
Onboarding experience suffers during the phase that sets the tone for the entire relationship |
Two of these deserve emphasis.
First, the elapsed-time killer in implementation projects is typically data gathering and reformatting, not system configuration. Leaders at global payroll providers identify the data phase as the single biggest blocker to faster go-lives.
Second, the repetition is the silent cost. When the second client arrives from the same source system, the conversion work often starts from scratch, because nothing from the first project was captured in a reusable form. Your team solves the same mapping puzzle repeatedly and pays for it every time.
How AI-powered data mapping closes the gap
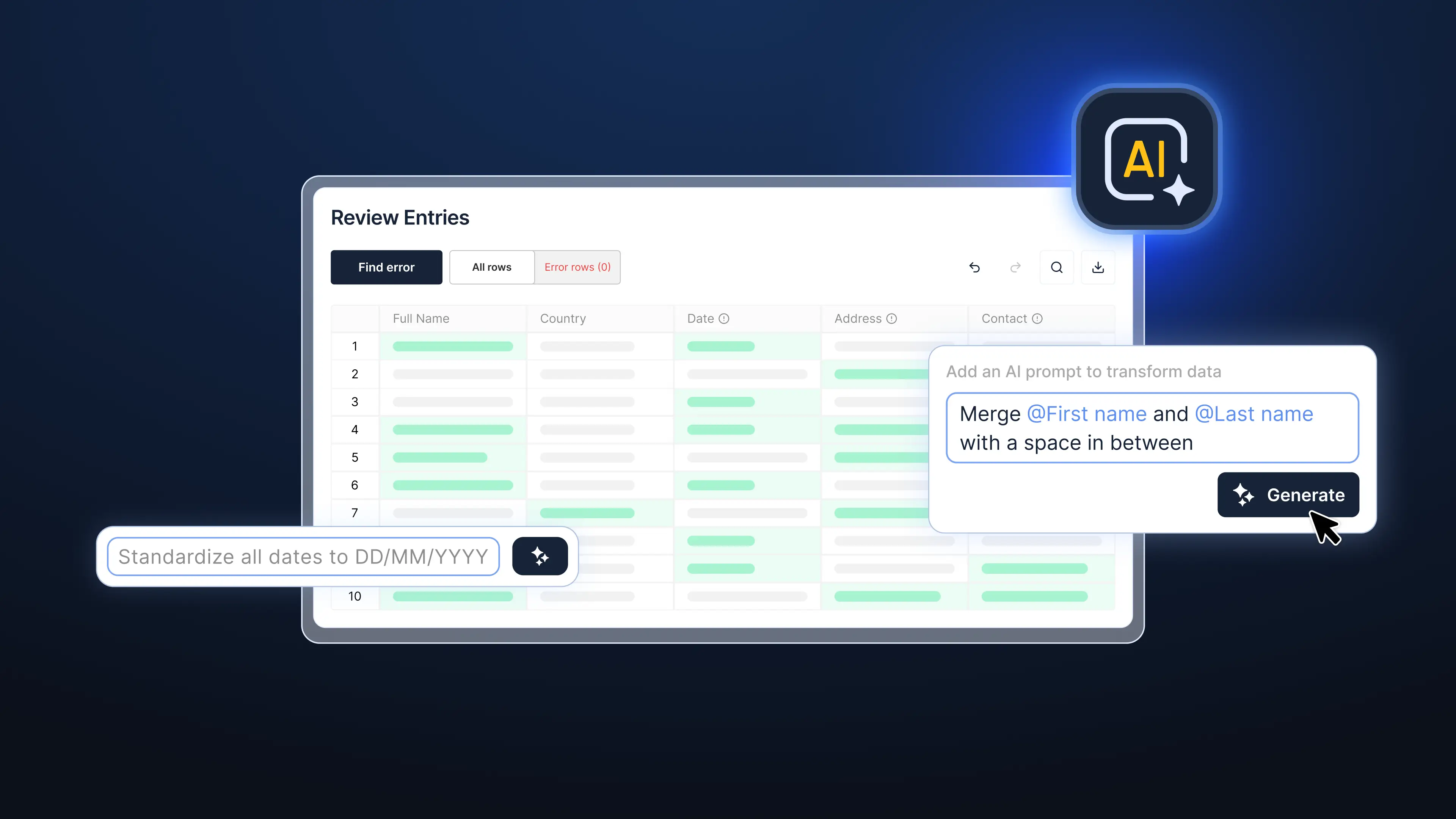
AI-powered data mapping inverts the template logic. Instead of forcing every source into one rigid input format, it reads the customer file as it arrives and translates it into your system’s required structure. The work follows three steps: map, validate, clean.
- Map. AI-powered mapping matches incoming columns to your target data model regardless of naming, ordering, or position in the sheet. Employee number, payroll ID, and works number resolve to the same target field. Multi-sheet workbooks and fragmented reports can be merged on the correct identifier instead of by hand.
- Validate. Format rules move out of hover comments and into enforced checks that run before import, not after. Date formats, ID structures, and country-specific requirements get flagged while the data is still in front of you, which can turn the multi-round email loop into a single review pass.
- Clean. Detected issues are corrected in place – formats standardized, values transformed, gaps surfaced for the client to fill once rather than over weeks of back-and-forth.
The compounding benefit sits in the mapping step: once a source format has been mapped, the next client from that provider doesn’t start from zero. The format gap gets closed once per source system instead of once per client.
The trust questions, answered honestly
Payroll data leaves little room for error, and the skepticism implementation leaders voice about AI is consistent across conversations. Three questions come up repeatedly, and they’re the right ones to ask any vendor:
- “Will AI hallucinate my payroll data?” AI should propose the mapping; deterministic, inspectable rules should execute the transformation. Suggestions stay reviewable by your team before anything is applied.
- “Do we lose control over changes?” The bar to set: every modification logged, row by row, so you can show the client exactly what changed and why. Manual spreadsheet work, by contrast, leaves no audit trail at all.
- “Does this need engineers?” For most payroll service organizations, engineering resources range from scarce to unavailable. The mapping, validation, and cleaning workflow has to be operable by implementation consultants themselves, with no code involved.
Keep the templates, build, or buy?
Three realistic paths exist, and the right one depends on your format variety, onboarding volume, and available engineering capacity:
| Option |
What it solves |
Where it breaks |
| Keep refining templates |
Low upfront cost; familiar process |
The manual conversion work remains; capacity stays tied to headcount; client friction persists |
| Build internal scripts |
Tailored to your exact systems |
Scripts and macros tend to break on edge cases; they require engineering capacity most service organizations don’t have; maintenance grows with every new source format |
| Buy data onboarding infrastructure |
Mapping, validation, and cleaning handled at the file level; reusable source-format knowledge |
Requires vendor evaluation, security review, and a business case |
Implementation teams that have tried the build route describe the same trajectory: the script works for the formats it was written for, then a client moves a header row or a new provider appears, and the fix lands back on whoever built it. The honest evaluation question isn’t whether your team could build a converter – it’s whether maintaining one across dozens of evolving source formats is where you want your scarce technical capacity to go.
Closing the payroll data format gap with Ingestro
The format gap doesn’t close by perfecting your template. It closes when incoming client data is translated into your system’s format at the file level, with upfront validation and every change accounted for.
Before evaluating any solution, put numbers on your own gap:
- How many hours per new client does your team spend converting customer files into your import format?
- How many template variations does your team maintain today?
- How many rounds of client back-and-forth does a typical onboarding need before the first import succeeds?
- How much of your format knowledge exists only in senior consultants’ heads?
If those numbers describe your growth ceiling, it may be worth seeing how AI-powered data mapping handles your messiest real-world customer files.
Ingestro provides the data infrastructure built to close exactly this gap. Through AI automation, your implementation and operations teams can map payroll data across formats and sources quickly and efficiently.
For implementation and operations leaders, three benefits matter most:
- AI proposes, rules execute. Ingestro AI suggests the mapping from the client’s format to your target data model; your consultants review and confirm. The applied transformations are deterministic and inspectable, not a black box.
- Every change is accountable. Each row-level modification is logged, so client approvals and audit questions have immediate answers – a step up in visibility from manual spreadsheet work.
- Source formats become assets. Once your team has onboarded one client from a given legacy provider, that mapping knowledge carries forward, so repeat formats stop consuming repeat effort.
The result is a shift in what your consultants spend their days on: less time reformatting spreadsheets thanks to Ingestro AI, more time on the client conversations that determine whether an onboarding builds trust or burns it.


.png)
.png)